Accelerating Python Analytics by
In-Database Processing
PyData Berlin 2016
Edouard Fouché
IBM Research & Development
20/05/2016

About me¶

Edouard Fouché¶
- M.Eng. from ESIEE PARIS
- Graduate CS student at Karlsruhe Institute of Technology (KIT)
- Interested in Machine Learning & Cloud Computing
- Working student at IBM since April ’15
- Developing Python tools for in-database analytics
Outline¶
- Motivations
- Python for data science
- Limitations
- Solutions
- Bringing analytics to the data
- IBM dashDB
- Python/SQL
- Ibmdbpy
- Demo !
- Conclusion/Discussion
Motivations¶
- The Python ecosystem for Data Science is rich
- Scipy, Numpy, Pandas
- Scikit-learn
- Matplotlib, Seaborn, Bokeh
- IPython notebooks...

Performance Limitation¶
- CPU, RAM
- Laptop / Workstation
Data Extraction¶
- Data is typically stored in data warehouses
- Big data volumes are impractical to extract
Solutions¶
Out-of-core: Data does not fit in the main memory
- In-Workstation computation, e.g. Dask
- In-Cluster computation, e.g. Hadoop, Spark
- In-Database computation
- Directly in the database engine
In-Database computation¶
Advantageous for several reasons:
- Databases are everywhere !
- Efficiency and scalability
- Data freshness
- Security

- Cloud-based data warehousing system
- Optimized for analytics and data mining
- Integrates BLU technology
- Data compression
- In-memory column store
- Massive Parallel Processing (MPP) scale-out

Task: Compute the mean for each column given the class in the IRIS data set
SELECT AVG(PETALLENGTH), AVG(PETALWIDTH),
AVG(SEPALLENGTH), AVG(SEPALWIDTH)
FROM IRIS
GROUP BY SPECIES
- Only one line in Pandas
In [21]:
from ibmdbpy.sampledata import iris
In [22]:
iris.groupby("species").mean()
Out[22]:

- Pandas-like interface for multiple backends
- Translates Python code into something else (e.g. SQL)
- Supports a lot of backends
However
- Only a subset of functions for each backend
- Cannot make use of backends' specific functions

The SQL-Pushdown approach¶
We translate higher level syntax into SQL
We push them to the underlying database
Everything happens transparently
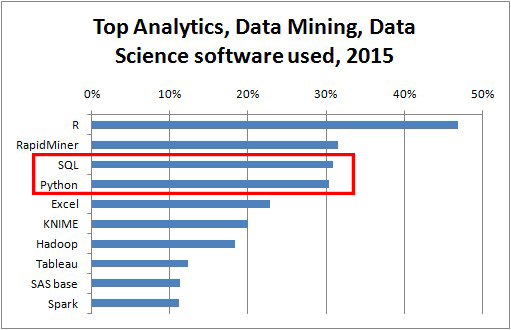 source : KDnuggets 2015
source : KDnuggets 2015
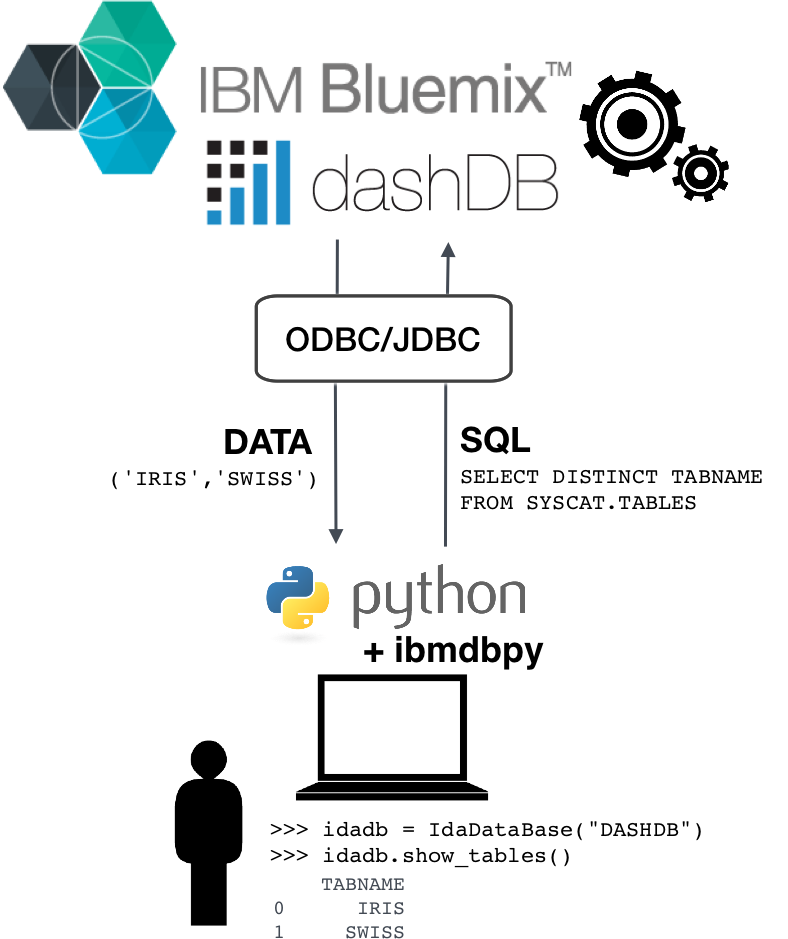
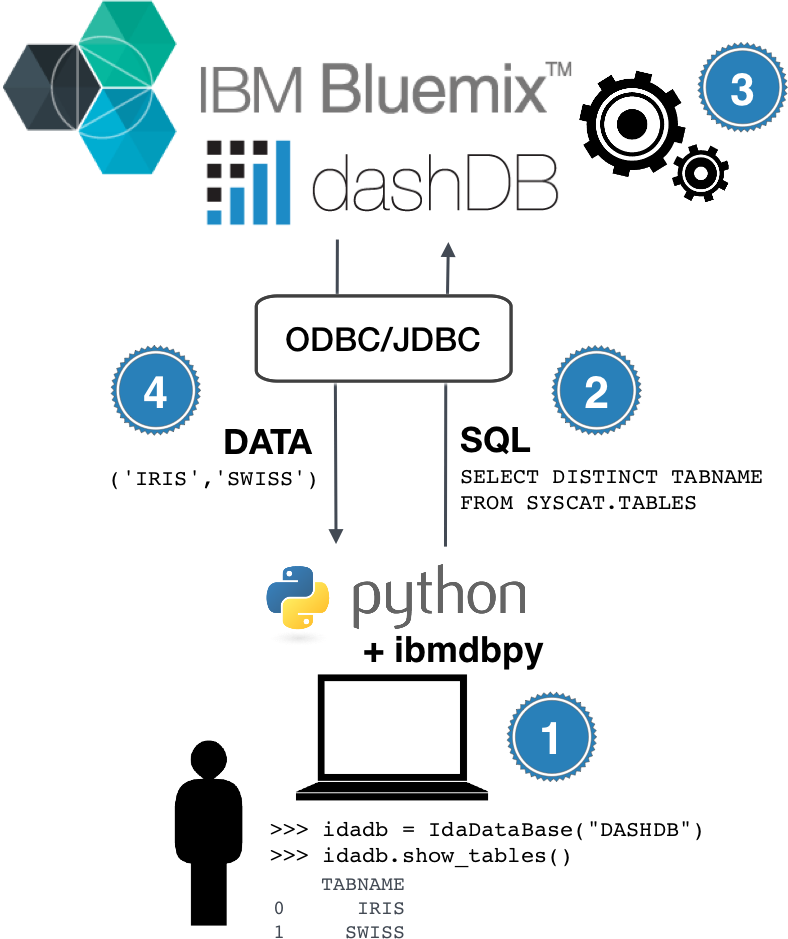
ibmdbpy¶
- Pandas-like interface for IBM dashDB
- Compatible Python 2.7 up to 3.5
- ODBC or JDBC connection (cross-platform)
- Data analytics
- Database administration
Demo¶
Connect to the database¶
In [23]:
from ibmdbpy import IdaDataBase
idadb = IdaDataBase("DASHDB", verbose=True)
IdaDataBase instances are an abstraction layer for the connection to dashDB
- IDA : In-Database-Analytics
- Database administration
- Database lookup
- Upload Pandas.DataFrame, Download Table
- Drop tables, create views...
Open a pointer to a table¶
In [24]:
from ibmdbpy import IdaDataFrame
iris = IdaDataFrame(idadb, "IRIS", indexer = "ID") # IRIS dataset
- An IdaDataFrame instance is a pointer to a table in the database
- Data Manipulation
- Non-destructive data manipulation
- Statistics, filtering, sorting...
- Pandas-like syntax
In [25]:
iris.head()
Out[25]:
Simple statistics¶
In [26]:
iris.corr()
Out[26]:
In [27]:
iris.describe()
Out[27]:
Data manipulation¶
In [28]:
iris = iris[["ID","SEPALLENGTH", "SEPALWIDTH"]]
In [29]:
iris['new'] = iris['SEPALLENGTH'] + iris['SEPALWIDTH'].mean()
In [30]:
iris.head()
Out[30]:
Data stays in the database¶
In [31]:
iris
Out[31]:
In [32]:
iris.print()
Machine Learning¶
- IBM dashDB is more than just a database
- Includes in-database Data Mining algorithms
- Currently available in ibmdbpy :
- K-means, Naive Bayes, Association Rules
- ...
K-means Clustering¶
- Sklearn-like
In [33]:
from ibmdbpy.learn import KMeans
kmeans = KMeans(3) # clustering with 3 clusters
In [34]:
iris = IdaDataFrame(idadb, "IRIS", indexer = "ID")
In [35]:
kmeans.fit_predict(iris).head()
Out[35]:
In [36]:
kmeans.describe()
Sneak preview¶
- In-database Feature Selection
In [37]:
iris = IdaDataFrame(idadb, "IRIS_DISC", indexer="ID")
In [38]:
from ibmdbpy.feature_selection import info_gain
info_gain(iris)
Out[38]:
Performance comparison¶
- Comparing in-database and in-memory variant
- in-database: IBM dashDB entry plan on Bluemix
- in-memory: Notebook, i5 2.6GHz - 16GB RAM
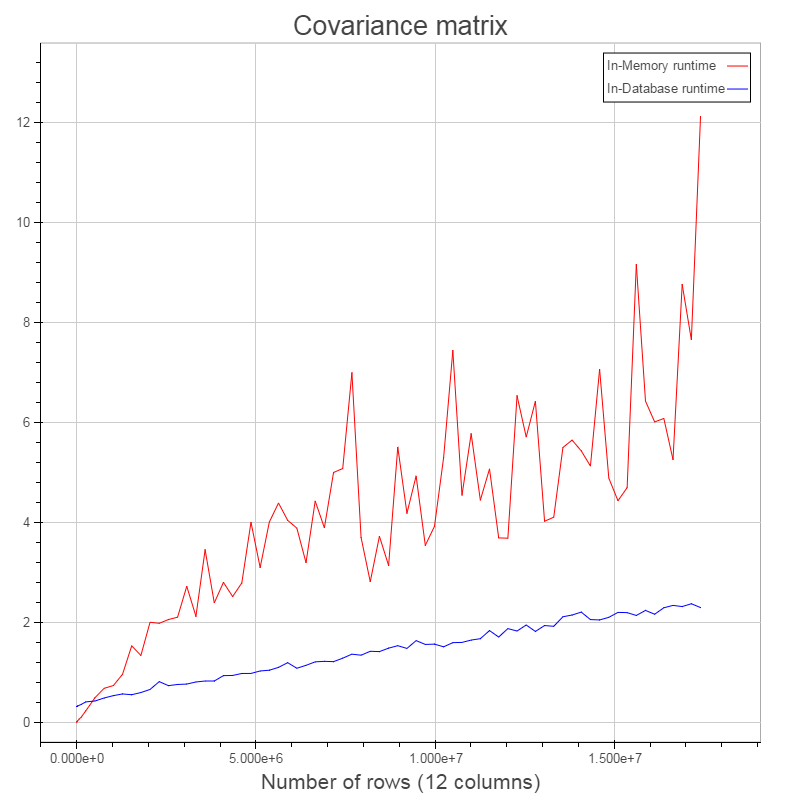
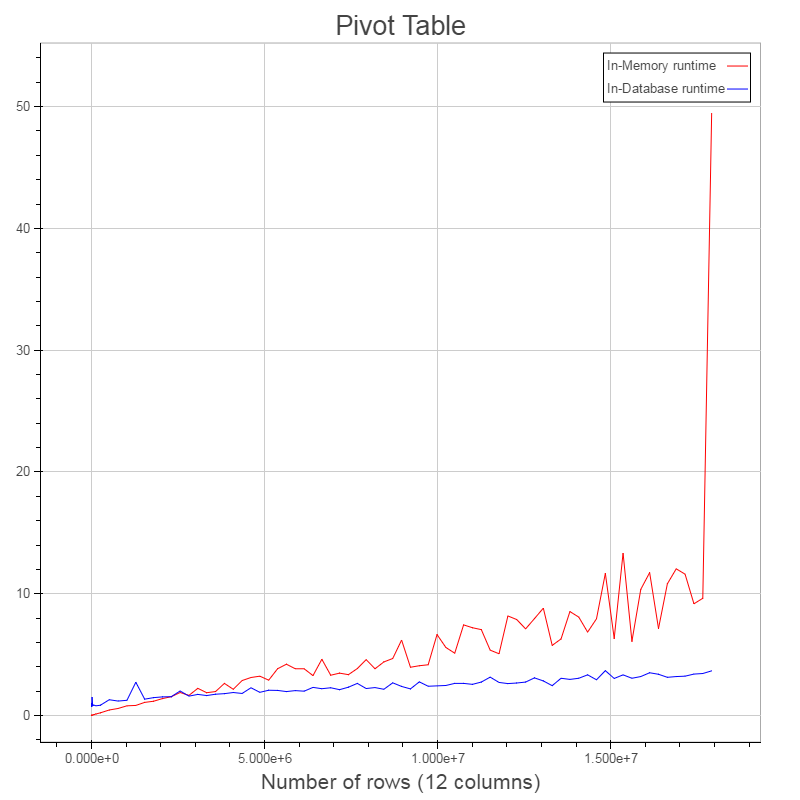
Deployment¶
- Distribution via PyPI
pip install ibmdbpy
- Available on GitHub: https://github.com/ibmdbanalytics/ibmdbpy
- License : BSD
Future work¶
- Full test coverage
- More features coming soon:
- Merge, sampling
- More ML wrappers
- In-Database Feature Selection
- In-Database Geospatial Analytics
Conclusion¶
- Ibmdbpy is an interface for in-database computing
- Relies on the database engine
- No data extraction required
- Data freshness
- Security
- Intuitive: Pandas-like, Sklearn-like syntax
- Shows great performance on "big" datasets
- However:
- Requires to connect to a remote database instance
- Designed only for IBM dashDB / IBM DB2
- Covers only a small part of Python analytics capabilities
- Note: For R users, we have a similar interface for R: ibmdbR
Thank you for your attention !¶
Any questions, suggestions ?


In-Database Processing
PyData Berlin 2016
Edouard Fouché
IBM Research & Development
20/05/2016
About me¶
Edouard Fouché¶
- M.Eng. from ESIEE PARIS
- Graduate CS student at Karlsruhe Institute of Technology (KIT)
- Interested in Machine Learning & Cloud Computing
- Working student at IBM since April ’15
- Developing Python tools for in-database analytics
Outline¶
- Motivations
- Python for data science
- Limitations
- Solutions
- Bringing analytics to the data
- IBM dashDB
- Python/SQL
- Ibmdbpy
- Demo !
- Conclusion/Discussion
Motivations¶
- The Python ecosystem for Data Science is rich
- Scipy, Numpy, Pandas
- Scikit-learn
- Matplotlib, Seaborn, Bokeh
- IPython notebooks...
Performance Limitation¶
- CPU, RAM
- Laptop / Workstation
Data Extraction¶
- Data is typically stored in data warehouses
- Big data volumes are impractical to extract
Solutions¶
Out-of-core: Data does not fit in the main memory
- In-Workstation computation, e.g. Dask
- In-Cluster computation, e.g. Hadoop, Spark
- In-Database computation
- Directly in the database engine
In-Database computation¶
Advantageous for several reasons:
- Databases are everywhere !
- Efficiency and scalability
- Data freshness
- Security
- Cloud-based data warehousing system
- Optimized for analytics and data mining
- Integrates BLU technology
- Data compression
- In-memory column store
- Massive Parallel Processing (MPP) scale-out
Task: Compute the mean for each column given the class in the IRIS data set
SELECT AVG(PETALLENGTH), AVG(PETALWIDTH), AVG(SEPALLENGTH), AVG(SEPALWIDTH) FROM IRIS GROUP BY SPECIES
- Only one line in Pandas
In [21]:
from ibmdbpy.sampledata import iris
In [22]:
iris.groupby("species").mean()
Out[22]:
- Pandas-like interface for multiple backends
- Translates Python code into something else (e.g. SQL)
- Supports a lot of backends
However
- Only a subset of functions for each backend
- Cannot make use of backends' specific functions
The SQL-Pushdown approach¶
We translate higher level syntax into SQL
We push them to the underlying database
Everything happens transparently
source : KDnuggets 2015
ibmdbpy¶
- Pandas-like interface for IBM dashDB
- Compatible Python 2.7 up to 3.5
- ODBC or JDBC connection (cross-platform)
- Data analytics
- Database administration
Demo¶
Connect to the database¶
In [23]:
from ibmdbpy import IdaDataBase
idadb = IdaDataBase("DASHDB", verbose=True)
IdaDataBase instances are an abstraction layer for the connection to dashDB
- IDA : In-Database-Analytics
- Database administration
- Database lookup
- Upload Pandas.DataFrame, Download Table
- Drop tables, create views...
Open a pointer to a table¶
In [24]:
from ibmdbpy import IdaDataFrame
iris = IdaDataFrame(idadb, "IRIS", indexer = "ID") # IRIS dataset
- An IdaDataFrame instance is a pointer to a table in the database
- Data Manipulation
- Non-destructive data manipulation
- Statistics, filtering, sorting...
- Pandas-like syntax
In [25]:
iris.head()
Out[25]:
Simple statistics¶
In [26]:
iris.corr()
Out[26]:
In [27]:
iris.describe()
Out[27]:
Data manipulation¶
In [28]:
iris = iris[["ID","SEPALLENGTH", "SEPALWIDTH"]]
In [29]:
iris['new'] = iris['SEPALLENGTH'] + iris['SEPALWIDTH'].mean()
In [30]:
iris.head()
Out[30]:
Data stays in the database¶
In [31]:
iris
Out[31]:
In [32]:
iris.print()
Machine Learning¶
- IBM dashDB is more than just a database
- Includes in-database Data Mining algorithms
- Currently available in ibmdbpy :
- K-means, Naive Bayes, Association Rules
- ...
K-means Clustering¶
- Sklearn-like
In [33]:
from ibmdbpy.learn import KMeans
kmeans = KMeans(3) # clustering with 3 clusters
In [34]:
iris = IdaDataFrame(idadb, "IRIS", indexer = "ID")
In [35]:
kmeans.fit_predict(iris).head()
Out[35]:
In [36]:
kmeans.describe()
Sneak preview¶
- In-database Feature Selection
In [37]:
iris = IdaDataFrame(idadb, "IRIS_DISC", indexer="ID")
In [38]:
from ibmdbpy.feature_selection import info_gain
info_gain(iris)
Out[38]:
Performance comparison¶
- Comparing in-database and in-memory variant
- in-database: IBM dashDB entry plan on Bluemix
- in-memory: Notebook, i5 2.6GHz - 16GB RAM
Deployment¶
- Distribution via PyPI
pip install ibmdbpy
- Available on GitHub: https://github.com/ibmdbanalytics/ibmdbpy
- License : BSD
Future work¶
- Full test coverage
- More features coming soon:
- Merge, sampling
- More ML wrappers
- In-Database Feature Selection
- In-Database Geospatial Analytics
Conclusion¶
- Ibmdbpy is an interface for in-database computing
- Relies on the database engine
- No data extraction required
- Data freshness
- Security
- Intuitive: Pandas-like, Sklearn-like syntax
- Shows great performance on "big" datasets
- However:
- Requires to connect to a remote database instance
- Designed only for IBM dashDB / IBM DB2
- Covers only a small part of Python analytics capabilities
- Note: For R users, we have a similar interface for R: ibmdbR
Thank you for your attention !¶
Any questions, suggestions ?